
Some details about the history
It all started with HTTP/0.9 which came out in 1991, which was designed just for websites which were just documents with basic texts. It had methods like GET, POST and HEAD.
Then in 1996, came HTTP/1.0 wherein we got to see support for other kind of media as well. New methods came into picture - PUT, DELETE, LINK and UNLINK.
Just after a year, in 1997, HTTP/1.1 came, which addressed many issues reported in HTTP/1.0.
For cross origin communication, new method - OPTIONS was introduced in H1.1, along with options for caching. But most importantly, keep-alive was added in H1.1.
It really converted from Hyper text to Hyper media as full fledged applications with images and sounds as well were on the rise.
There were flaws in H1.X for which people started using workarounds or hacks to get around them like minification, gzipping, sharding and other techniques to increase the performance of the site.
Some flaws that came with H1.X
Head of line (HOL) Blocking
Its a phenomenon which occurs when a TCP connection that has been established between the client and the server to cater to a resource is blocked or is idle until the server has responded with the requested resource.
Hence, resources were only be allowed to be requested one at a time, one after the other.
Browsers tried to get ahead of this problem by allowing first 2 concurrent connections to the server and then bumping it up to 6 concurrent connections.
Meta Data
With HTTP1.X, we saw that a lot of meta data was being attached to each and every request which were also repeated in almost all of the requests.
Headers like User-Agent, Content-Encoding, and cookies always appear in requests which are not compressed when compression techniques like gzip and brotli have been used.
Access tokens or session UUIDs are shared with almost all requests which are long and static which really adds to the utilized bandwidth.
Glorious Era of HTTP/2.0
H2 came in 2015, and introduced the concept of streams. It said that instead of having 6 active connections, we will utilize a single TCP connection to the fullest by sending streams of data.
Those who all were on H1.X will still be valid as H2 is just an upgrade over H1.X. The request-response paradigm and the way data and headers are coded will be the same. The only difference is in the encoding of data which is sent over the wire.
Streams are furthermore chopped into frames and are put onto the connection. if a stream is blocked by either waiting for server to respond back with the data or for the client to send another stream, another stream will utilize the bandwidth.
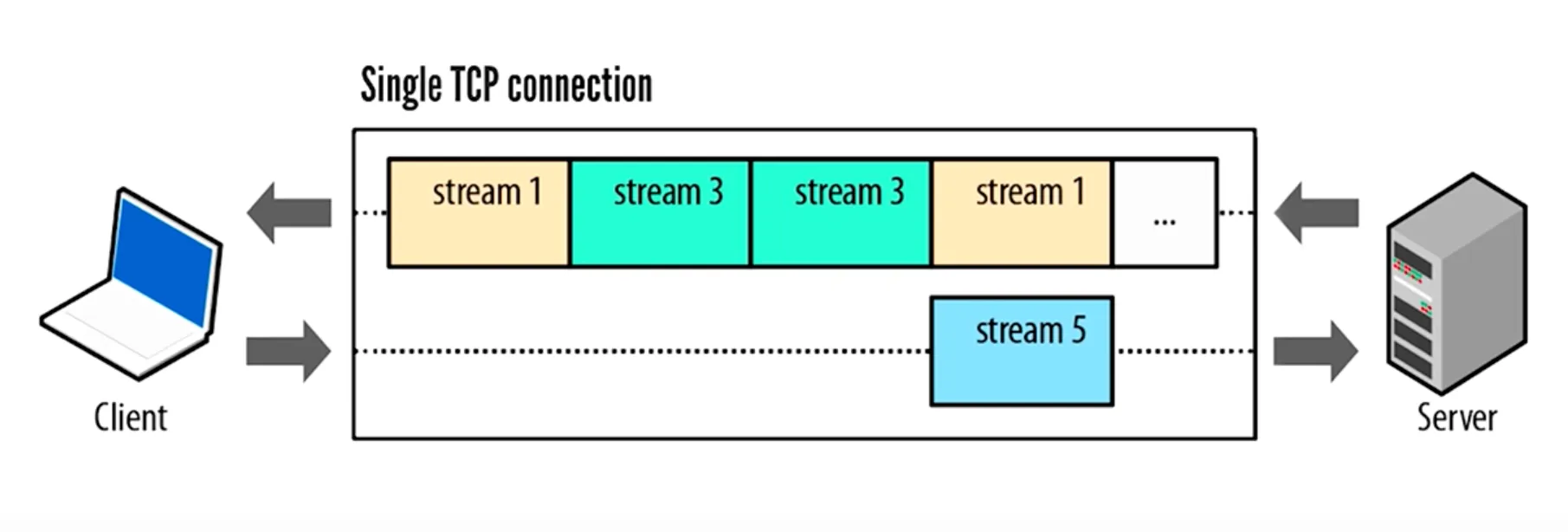
A stream is nothing but a resource that is needed for the website and contains a header and a data section, which are inturn chopped into a header frame and a data frame respectively and are put onto the single TCP connection.
HPACK
One of the advantages of having headers in a separate frame is that now they can be encrypted and decrypted or gzipped just like the data frame as well.
And the utility that does this is called HPACK.
HPACK also makes sure that the commonly occuring headers are cached and the values are referenced from a table of such cached headers.
This all increases the performance significantly.
HTTP Push
This is a very unique and simple concept where in when a request is made for a resource from the client, server responds with all the resources that is associated with the requested resource.
Server is sending something for which client didn’t ask but will definitely need.

Such frames which are associated with related data are called push promise frames. Such responses are cached at the client side as well to increase performance even further.
Other things about HTTP/2.0
All of the data that is sent over the wire are TLS encrypted and H2 also invalidates the use of all the hacks or workarounds that were present at the time of H1.X.
Clients can actually add weights or priorities to different streams if they want one kind of data quicker than the other kind.
